
Wie das Crawlen und Indexieren von Webseiten gesteuert werden kann, erfahren Sie hier.
Um das Crawlen und Indexieren von Webseiten zu steuern, bieten sich verschiedene Werkzeuge an. Für viele Webmaster ist es schwierig zu unterscheiden, wann der Einsatz der robots.txt zu empfehlen ist und wann man sinnvoller Meta-Robots-Tags verwendet.
Zwei der grundlegenden SEO-Fragen lauten:
1. Wann und zu welchem Zweck sollte man die robots.txt-Datei verwenden? und
2. Wie unterscheidet sich deren Einsatz von Anweisungen per Meta-Robots-Tag wie „noindex“ und „nofollow“?
Dazu muss man zunächst wissen, wie Suchmaschinen funktionieren. Bevor eine Seite im Index einer Suchmaschine landen kann, muss sie im ersten Schritt gecrawlt werden. Das übernehmen sogenannte Crawler wie der Googlebot. Dabei werden die Inhalte der Seite ausgelesen und vorverarbeitet.
Wenn eine Seite gecrawlt wurde, geht es im nächsten Schritt darum, ob und welche Inhalte der Seite indexiert werden. Google und andere Suchmaschinen können die Inhalte einer Seite nur dann indexieren, wenn die Indexierung freigegeben bzw. nicht gesperrt ist.
Hinsichtlich dieser beiden Schritte gilt: Das Crawlen wird über die robots.txt gesteuert, das Indexieren über Meta-Robots-Tags.
Das bedeutet aber auch: Wenn eine bestimmte Seite per robots.txt über eine „disallow“-Anweisung gesperrt ist, kann der Crawler diese Seite nicht erfassen und wird damit auch nicht erkennen, ob diese indexiert werden soll oder nicht. Das kann zu unerwünschten Folgen führen (siehe dazu den entsprechenden Abschnitt unten).
Welche Einstellungen in robots.txt und Meta-Robots-Tags sind die richtigen?
Um also zu beurteilen, wie die richtigen Einstellungen für eine Seite in der robots.txt und den Meta-Robots-Tags gewählt werden sollten, müssen die folgenden Fragen beantwortet werden:
- Soll die Seite gecrawlt und sollen die auf ihr vorhandenen Inhalte indexiert werden? Dann darf die Seite nicht durch „disallow“ in der robots.txt gesperrt sein, bzw. es muss eine explizite Freigabe für diese Seite per „allow“ geben. Zusätzlich darf die Seite nicht durch ein „noindex“ im Meta-Robots-Tag gegen Indexierung gesperrt sein.
- Soll die Seite gecrawlt, aber nicht indexiert werden? Dass kann dann sinnvoll sein, wenn sich auf einer Seite wichtige Links befinden, denen die Suchmaschinen folgen sollen. In diesem Fall darf ebenfalls kein „disallow“ in der robots.txt für die Seite gesetzt sein. Das passende Meta-Robots-Tag wäre hier „noindex“. Ein „nofollow“ darf dagegen nicht gesetzt werden, weil der Googlebot und andere Crawler den auf der Seite vorhandenen Links dann nicht folgen würden.
- Soll die Seite weder gecrawlt noch indexiert werden? In diesem Fall genügt ein „disallow“ in der robots.txt, wenn die Seite noch nicht indexiert ist. Wenn die Seite schon indexiert ist, handelt es sich um einen Sonderfall – siehe dazu den folgenden Abschnitt.
Unerwünschte Folgen durch die robots.txt
Was passiert, wenn eine Seite beispielsweise schon im Google-Index gelistet ist und sie dann für den Googlebot per „disallow“ in der robots.txt gesperrt wird? Eine solche Situation kann entstehen, wenn ein Webmaster versucht, eine Seite per robots.txt aus dem Index zu entfernen – was nicht funktioniert.
Dann geschieht nämlich Folgendes: Im beschriebenen Beispiel darf der Googlebot die Seite nicht mehr crawlen – kann also auch nicht mehr feststellen, welche Inhalte und welche Metadaten sich auf dieser Seite befinden.
Die Seite bleibt aber weiterhin im Index – sie wird somit auch weiterhin in den Suchergebnissen angezeigt. Leider wird Google aber mangels entsprechender Informationen zu den Metadaten wie der Meta-Description, die ja nicht mehr gecrawlt werden dürfen, diese auch nicht mehr anzeigen. Stattdessen erscheint ein Hinweis wie dieser:
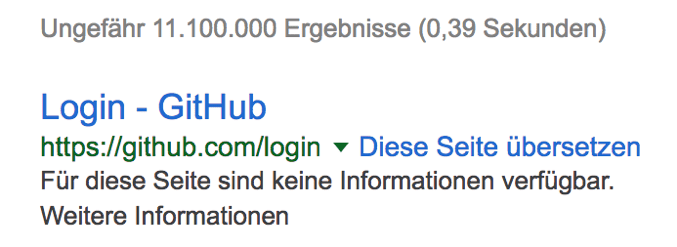
Wenn also eine bereits indexierte Seite aus dem Index der Suchmaschinen entfernt werden soll, muss zunächst sichergestellt sein, dass diese auch weiterhin crawlbar ist. Sie darf also nicht per robots.txt gesperrt sein.
Zudem muss auf der Seite (oder alternativ per HTTP-Header) ein Meta-Robots-Tag gesetzt werden, das die Eigenschaft „noindex“ besitzt.
Ist die Seite dann aus dem Index entfernt, hat man wahlweise die Möglichkeit, diese zusätzlich per robots.txt zu sperren. In den meisten Fällen wird dies jedoch nicht notwendig sein.
Fazit
Wer den Unterschied zwischen der robots.txt und Meta-Robots-Tags verstehen möchte, muss die Arbeitsweise der Suchmaschinen kennen. Vor dem Indexieren der Inhalte ist das Crawlen der Seiten erforderlich. Das Crawlen kann per robots.txt gesteuert werden, das Indexieren per Meta-Robots-Tag. Vorsicht gilt bei Seiten, die bereits indexiert sind: Hier kann das Sperren per robots.txt zu unerwünschten Effekten auf den Suchergebnisseiten führen.
Haben Sie Fragen?
Möchten Sie mehr über den Unterschied zwischen robots.txt und Meta-Robots-Tags wissen? Brauchen Sie Unterstützung bei der Umsetzung auf Ihrer Webseite?






Online-Marketing Erfahrung seit 28 Jahren, in 87 Ländern
- 28 Jahre Erfahrung mit Suchmaschinenmarketing
- Lokale Spezialisten in 87 Ländern mit langjähriger Erfahrung (z.B. in China)
- Spezialisten mit Branchenerfahrung und Ausrichtung auf Ihre Businessziele
- Top-Positionen für die umsatzstärksten Suchbegriffe
- Sie erhalten neue Kunden, ohne Folgeinvestitionen.
- Sie erfahren, wie Sie Ihren Umsatz am stärksten erhöhen können.
- Sie profitieren von Erfahrungen in Ihren Exportmärkten.
- Sie profitieren von bewährten Prozessen.
- Weil Sie von jahrelanger Marketing- und Vertriebserfahrung profitieren und weil wir über breit aufgestellte Branchenkenntnisse verfügen.












